Abstract
TL;DR — GeoDiT-Ω is a single diffusion model that generates satellite imagery directly
from any geospatial primitive (polygons, polylines, boxes, or points), replacing task-specific pipelines with one
model that boosts downstream segmentation, detection, road extraction, and classification.
Generative models have achieved remarkable progress, yet applying them to satellite imagery
remains challenging. Unlike natural imagery, satellite scenes are structured by spatially
complex and semantically distinct geometries. Prior work addresses this complexity by adapting
natural image frameworks using dense rasters or sparse prompts, trading off annotation cost and
fidelity while breaking compatibility with vector primitives commonly used to represent
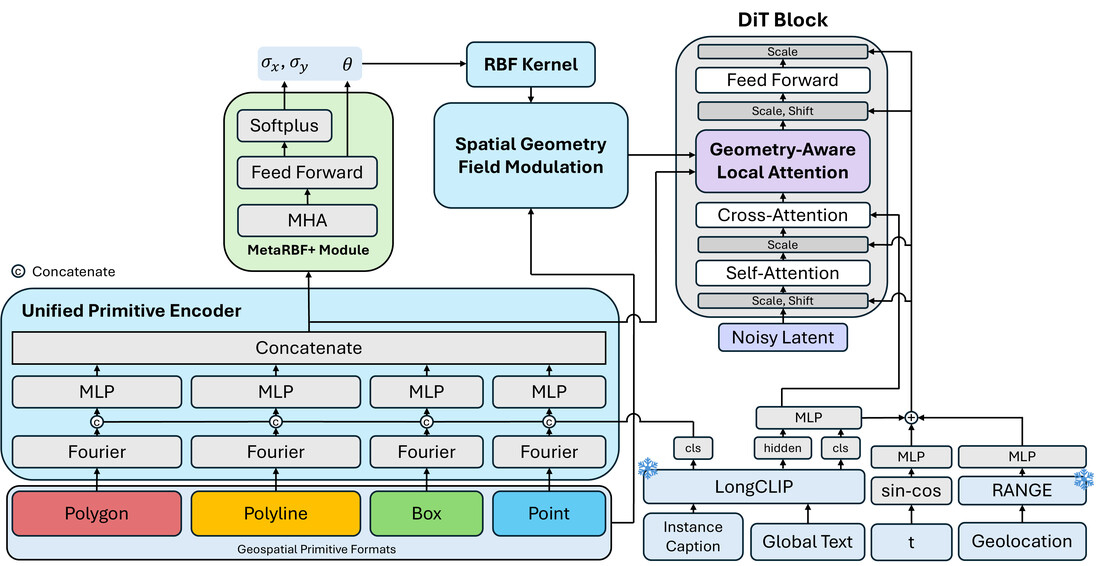
geographic information. We introduce GeoDiT-Ω, a unified spatial control framework that
generates satellite imagery directly from any native geospatial primitive. By jointly leveraging
precise annotations (polygons, polylines) and coarser ones (bounding boxes, points), the model
supports controllable layouts across varying annotation budgets, broadening applicability to
design tasks such as urban planning while remaining naturally compatible with end-to-end GeoAI
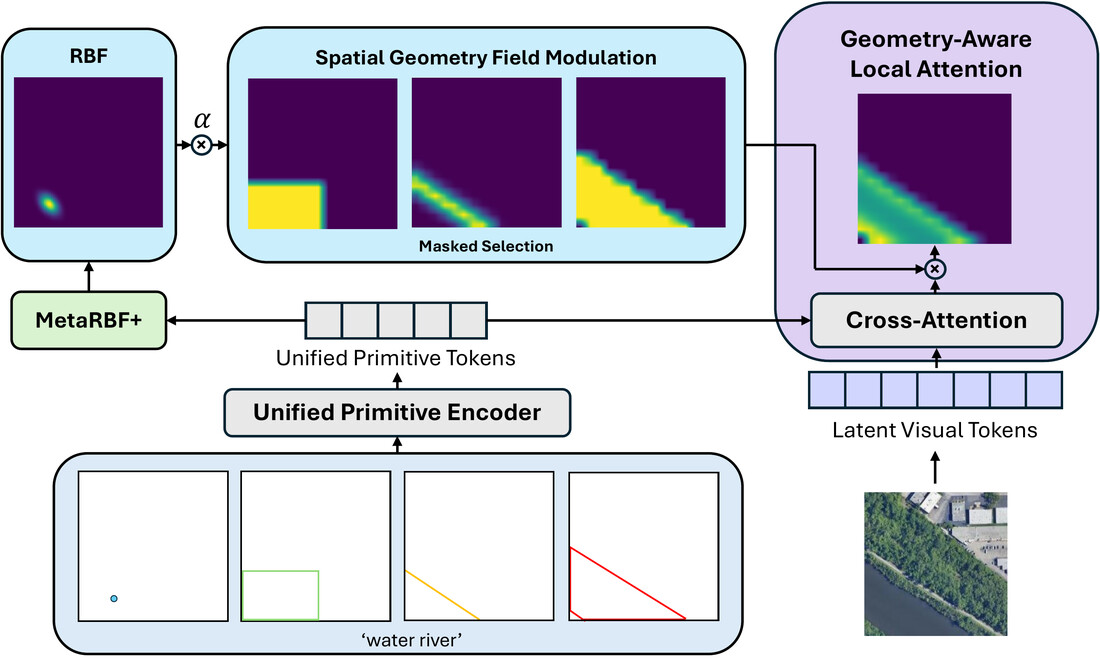
workflows. To effectively leverage these primitives during generation, we propose
Geometry-Aware Local Attention, a conditioning mechanism that injects explicit geometric cues
into the attention space. Across all conditioning formats, our approach consistently outperforms
both dense-control and sparse-control baselines. Furthermore, the flexibility of using
primitives enables controllable synthetic data augmentation for multiple remote sensing
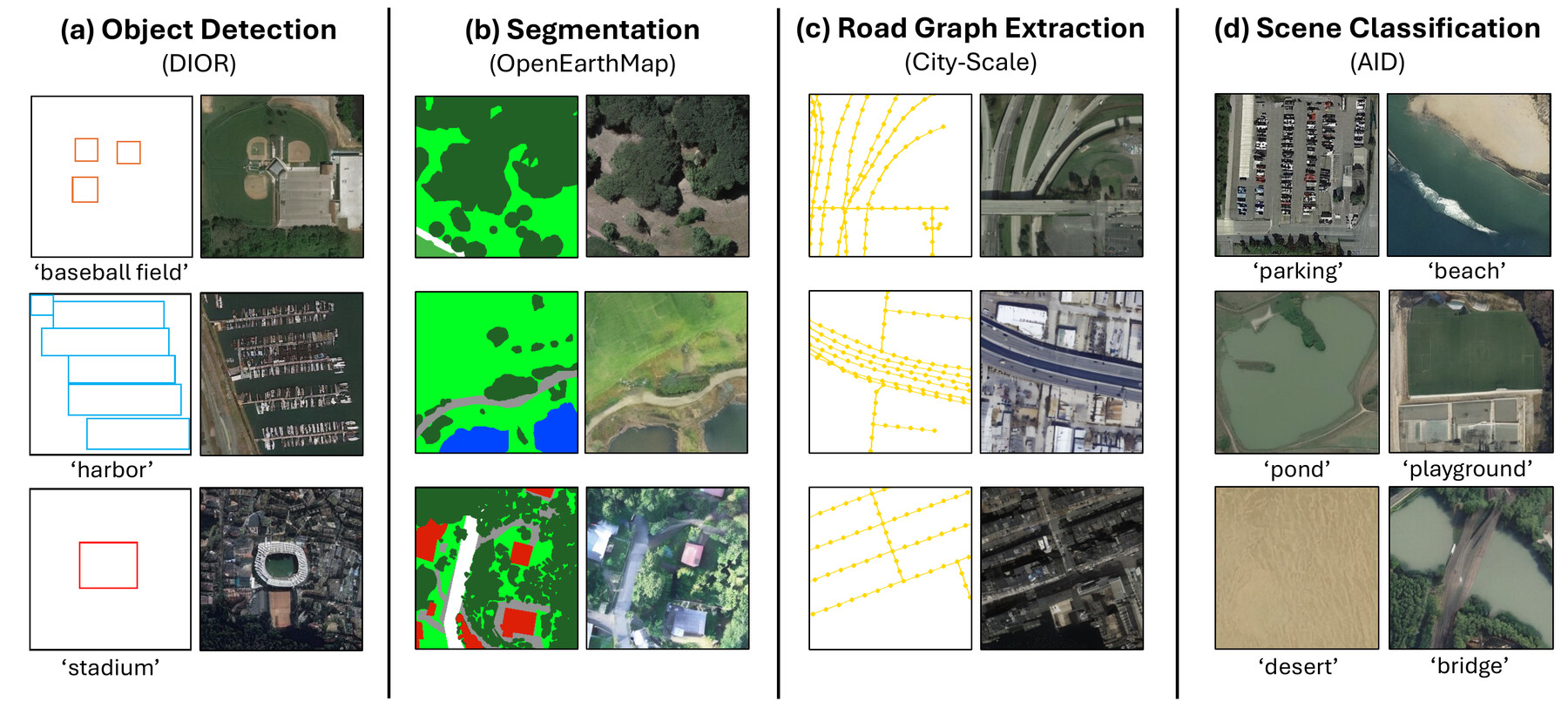
tasks where labeled scenes are costly to acquire. Using a single generative model rather than
task-specific pipelines, we improve performance on land-cover segmentation, object detection,
road graph extraction, and scene classification.